SQLD 35회 기출문제 오답노트!
전에 공부했던 걸로 무지성으로 기출문제 풀어보는 패기... 결과는 52점 처참...
정규화 (Normalization)
- 정규화는 데이터의 일관성, 최소한의 데이터 중복, 최소한의 데이터 유연성을 위해 데이터를 분해하는 과정이다.
- 정규화된 모델은 분해된 테이블 간에 부서코드로 조인(join)을 수행하며 하나의 합집합으로 만들 수 있다.
- 정규화를 하면 불필요한 데이터를 입력하지 않아도 되기 때문에 중복 데이터가 제거된다.
정규화 절차
| 정규화 절차 | 설명 |
| 제1정규화 | - 릴레이션의 속성 값이 모두 원자값(Atmoic Value) 만으로 구성되어야 한다. - 중복값을 제거한다. - 기본키를 설정한다. |
| 제2정규화 | - 기본키가 2개 이상의 속성으로 이루어진 경우, 부분 함수 종속성을 제거한다. |
| 제3정규화 | - 기본키를 제외한 컬럼 간의 종속성을 제거한다. 이행적 함수 종속성을 제거한다. |
| BCNF | - 기본키를 제외하고 후보기가 있는 경우, 후보키가 기본키를 종속시키면 분해한다. |
| 제4정규화 | - 여러 칼럼들이 하나의 컬럼을 종속시키는 경우, 분해하여 다중값 종속성(다치 종속성)을 제거한다. |
| 제5정규화 | - 조인에 의해서 종속성이 발생하는 경우 분해한다. |
정규화와 반정규화의 성능 이슈
- 정규화는 데이터 조회 시에 조인 연산을 유발하기 때문에 CPU, 메모리를 많이 사용한다.
- 조인으로 인하여 성능이 저하되는 문제를 반정규화로 해결할 수 있다.
- 반정규화는 데이터를 중복시키기 때문에 또 다른 문제점을 발생시킨다.
부분 함수 종속성 (Partial Functional Dependency)
릴레이션에서 기본키가 복합키일 경우 기본키를 구성하는 속성 중 일부에게 종속된 경우를 부분함수 종속이라고 한다.

위의 테이블에서 기본키는 (이름, 성별) 이다.
(이름, 성별) -> 주소
(이름, 성별) -> 지역번호
관계가 성립한다.
허나 이외의 관계도 성립한다.
기본키의 부분집합인 이름에 대해 (이름) -> (주소)의 관계가 성립한다.
이 경우가 기본키가 여러 속성으로 구성되어 있을 경우 기본키를 구성하는 속성 중 일부에게 종속된 경우이다.
이행적 함수 종속성 (Transitive Functional Dependency)
릴레이션에서 X, Y, X라는 3개의 속성이 있을 때 X -> Y, Y -> Z 이란 종속 관계가 있을 경우, X -> Z 가 성립될 때 이행적 함수 종속이라고 합니다.
즉, X를 알면 Y를 알고 그를 통해 Z를 알 수 있는 경우를 말합니다.
| 회원번호 | 이름 | 나이 | 거주지역 |
| A001 | 송민지 | 17 | 서울 |
| A002 | 박아람 | 15 | 부산 |
| A003 | 이예은 | 16 | 대전 |
이 릴레이션에서 '회원번호'를 알면 '이름'을 알 수 있고, '이름'을 알면 '나이'도 알 수 있습니다. 따라서 '회원번호'를 알면 '나이'를 알 수 있으므로 이행적 함수 종속 관계 입니다.
다중값 종속성 (Multi-Valued Dependency)
한 Relation에서 둘 이상의독립적인 다중값 속성이 존재하는 경우.
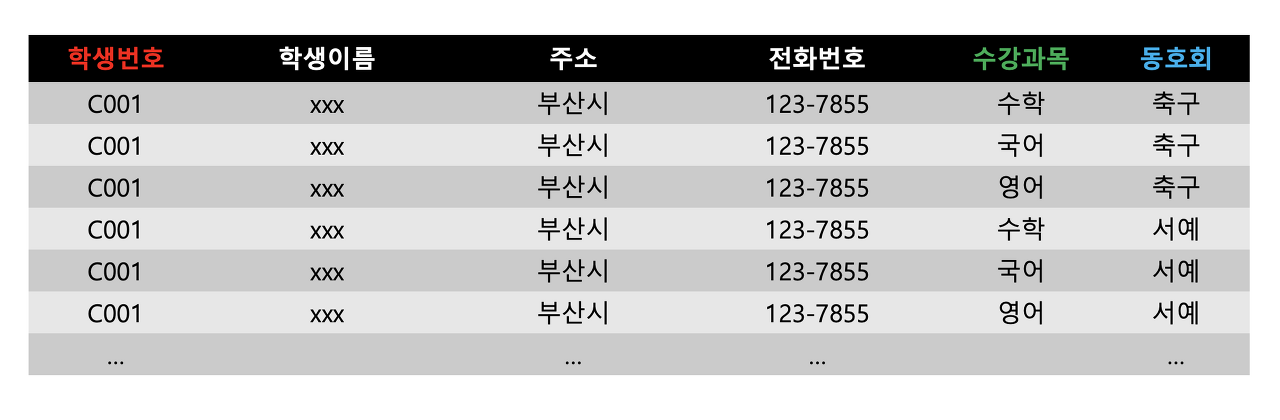
위 그림은 학생의 기본정보와 수강과목 동호회등 정보가 들어간 릴레이션이다.
수강과목은 3개, 동호회는 2개를 들은 것을 확인 할 수 있다. 하지만 여기서 하나의 과목을 더 듣게 되는 경우 동호회 정보를 넣어줘야하기 때문에 2개의 데이터(새로운 과목명 + 축구, 새로운 과목명 + 서예)를 넣어야 한다.
반대로 동호회를 하나 더 들을 경우 3개의 데이터가 추가되어야 한다. 이는 A(학생번호), B(수강과목), C(동호회)를 각각 다중결정하여 발생하는 것으로 불필요한 정보가 중복되는 현상이 발생된다.
이를 다중값 종속이라고 한다.
반정규화 (De-Normalization)
- 정규화된 엔터티, 속성, 관계에 대해 시스템의 성능향상과 개발과 운영(Maintenance)의 단순화를 위해 중복, 톡합, 분리 등을 수행하는 데이터 모델링의 기법
- 성능을 향상시키기 위해 정규화된 데이터 모델에서 중복, 통합, 분리 등을 수행하는 모든과정을 의미한다.
- 반정규화는 조회 속도를 향상시키지만, 데이터 모델의 유연성은 낮아진다.
반정규화를 수행하는 이유
- 데이터를 조회할 때 디스크 I/O량이 많아서 성능이 저하되는 경우
- 경로가 너무 멀어 조인으로 인한 성능저하가 예상되거나 칼럼을 계산하여 읽을 때 성능이 저하될 것이 예상되는 경우
* I/O는 입력(Input)/출력(Output)의 약자로, 컴퓨터 및 주변장치에 대하여 데이터를 전송하는 프로그램, 운영 혹은 장치를 일컫는 말
반정규화 절차
| 반정규화 절차 | 설명 |
| 대상 조사 및 검토 | 데이터 처리 범위, 통계성 등을 확인해서 반정규화 대상을 조사한다. |
| 다른 방법 검토 | 반정규화를 수행하기 전에 다른 방법이 있는지 검토한다. |
| 반정규화 수행 | 테이블, 속성, 관계 등을 반정규화 한다. |
*슈퍼 타입 및 서브 타입 변환 방법
| 변환 방법 | 설명 |
| OneToOne Type | 슈퍼 타입과 서브 타입을 개별 테이블로 도출한다. |
| Plus Type | 슈퍼 타입과 서브 타입 테이블로 도출한다 |
| Single Type | 슈퍼 타입과 서브 타입을 하나의 테이블로 도출한다. 조인 성능이 좋고 관리가 편하다. |
테이블과 칼럼의 반정규화는 데이터 무결성에 영향을 미치게 되나 관계의 반정규화는 데이터 무결성을 깨뜨릴 위험을 갖지 않고서도 데이터처리의 성능을 향상시킬 수 있는 반정규화의 기법이 된다.
데이터 모델 전체가 관계로 연결되어 있고 관계가 서로 먼 친척간에 조인관계가 빈번하게 되어 성능저하가 예상이 된다면 관계의 반정규화를 통해 성능향상을 도모할 필요가 있다.
슈퍼-서브타입 도출
슈퍼, 서브타입 엔터티 식별자의 도메인은 반드시 같아야한다.
슈퍼-서브타입 도출되는 과정 1

공통된 데이터만 사원 엔터티에 남기고(슈퍼타입)
기술직, 관리직만의 specialize된 속성들은 별도의 엔터티로 구성(서브타입)
슈퍼-서브타입 도출되는 과정2

각 엔터티의 공통된 데이터는 별도의 사원 엔터티로 구성하고(슈퍼타입)
기술직, 관리직만의 specialize된 속성들만 각 엔터티에 남김(서브타입)

두 서브타입간에 교집합이 없을 경우 배타적 exclusive 서브 카테고리 라고 하며, 위 그림과 같이 표기한다.
(기술직일 경우 관리직이 아니다 / 관리직일 경우 기술직이 아니다)
이 부분은 sqld 시험에는 포함되지 않는 내용이라 패스!
참고
- https://velog.io/@heewonim/DB-정규화와-반정규화
- https://cometruedream.tistory.com/50
- https://velog.io/@mindddi/DB모델링-관계슈퍼-서브타입
- https://dodo000.tistory.com/20
- https://velog.io/@busybean3/데이터베이스-함수-종속성Functional-Dependency
SQLD 문제 출처 :
'SQL' 카테고리의 다른 글
| [MSSql] index 인덱스 리빌드, 재구성(속도 향상) (0) | 2022.12.09 |
|---|---|
| [SQL] RANK(), DENSE_RANK(), ROW_NUMBER 개념 및 차이 (0) | 2022.11.01 |
| [SQL] 서브쿼리 종류 (0) | 2022.11.01 |
| [SQL] 트랜잭션의 ACID 성질 (0) | 2022.10.31 |
| [SQL] 데이터 모델링 - 관계 (Relationship) (0) | 2022.10.31 |



댓글