
1. Deep Feedforward Network (DFN)
DFN은 딥 러닝에서 가장 기본적으로 이용되는 인공신경망이다. 그림에서도 볼 수 있듯이 DFN은 입력층, 은닉층, 출력층으로 이루어져 있으며, 보통은 2개 이상의 은닉층을 이용한다. DFN에서 입력 데이터는 입력층, 은닉층, 출력층의 순서로 전파된다.

구조에서 알 수 있듯이 DNF은 현재 입력된 데이터가 단순히 입력층, 은닉층, 출력층을 거치면서 예측값으로 변환된 뒤에 현재 데이터에 대한 정보는 완전히 사라집니다. 즉, 입력되었던 데이터들의 정보가 저장되지 않기 때문에 입력 순서에 따라 데이터 간의 종속성이 존재하는 시계열 데이터를 처리하는 데는 한계점이 존재한다. 이러한 문제점을 해결하기 위해 제안된 것이 RNN 이다.
2. Recurrent Neural Network (RNN)
RNN으 시계열 데이터 (예를 들어, 문자열 및 센서 데이터)와 같이 시간적으로 연속성이 있는 데이터를 처리하기 위해 고안된 인공신경망이다. 시계열 데이터나 문자열은 일반적으로 앞에 입력된 데이터 (이전 시간의 데이터)에 의해 뒤에 입력된 데이터에 대한 예측이 영향을 받는다. 따라서, 단순히 현재 입력된 데이터를 입력층, 은닉층, 출력층의 순서로 전파하기마 하는 DFN으로는 시계열 데이터에 대한 정확한 예측이 어렵다.
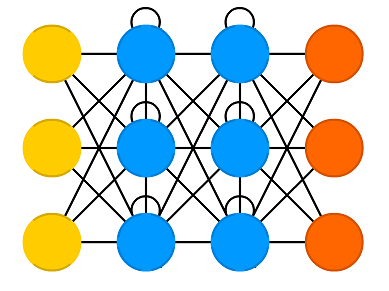
RNN은 그림과 같이 은닉층의각 뉴런에 순환 (recurrent) 연결을 추가하여 이전 시간에 입력된 데이터에 대한 은닉층의 출력을 현재 시간의 데이터를 예측할 때 다시 은닉층 뉴런에 입력한다. 이러한 방식으로 RNN은 이전 시간에 입력된 데이터를 같이 고려하며 현재 시간에 입력된 데이터에 대한 예측을 수행한다. 그러나 그림과 같이 단순한 형태의 RNN 역전파 (backpropagation) 알고리즘을 기반으로 오랜 시간에 걸쳐 경향성이 나타나는 데이터를 학습할 때 gradient가 비정상적으로 감소하거나 증가하는 vanishing/exploding gradient problem 이 발생한다는 문제점이 있다. 이를 해결하기 위해 제안된 것은 다음에 설명할 Long Short-Term Memory (LSTM) 이다.
3. Long Short-Term Memory (LSTM)
LSTM은 RNN에서 발생하는 vanishing/exploding gradient problem을 해결하기 위해 제안되었으며, 현재까지 제안된 RNN 기반의 응용들은 대부분 이 LSTM을 이용하여 구현되었다.
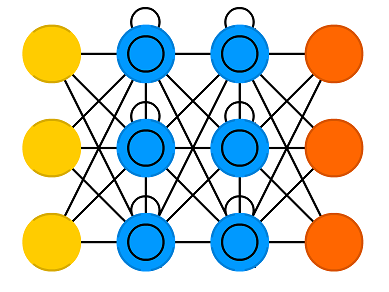
LSTM은 gradient 관련 문제를 해결하기 위해 forget gate, input gate, output gate라는 새로운 요소를 은닉층의 각 뉴런에 추가했다. 위 그림을 보면 기본적인 RNN의 구조에 memory cell이 은닉층 뉴런에 추가된 것을 볼 수 있으며, memory cell은 추가된 3개의 gate를 의미한다. LSTM에서 각 gate의 역할은 아래와 같다.
- Forget gate : 과거의 정보를 어느정도 기억할지 결정한다. 과거의 정보와 현재 데이터를 입력 받아 sigmoid를 취한 뒤에 그 값을 과거의 정보에 곱한다. 따라서, sigmoid의 출력이 0일 경우에는 과거의 정보를 완전히 잊고, 1일 경우에는 과거의 정보를 온전히 보존한다.
- Input gate : 현재의 정보를 기억하기 위해 만들어졌다. 과거의 정보와 현재 데이터를 입력 받아 sigmoid 와 tanh함수를 기반으로 현재 정보에 대한 보존량을 결정한다.
- Output gate : 과거의 정보와 현재 데이터를 이용하여 뉴런의 출력을 결정한다.
4. Autoencoder
데이터과 그에 대한 예측값 모두를 이용하여 입력 데이터에 대한 예측을 수행하도록 하는 것을 지도 학습(supervised learning)이라고 한다. 앞에서 소개란 DFN, RNN, LSTM을 비롯하여 대부분의 인공신경망은 지도학습 방식을 이용한다. 그러나 autoencoder는 이와 다르게 비지도 학습 (unsupervised learning)을 기반으로 학습된다. 따라서, autoencoder의 학습에서는 예측값이 필요하지 않다.
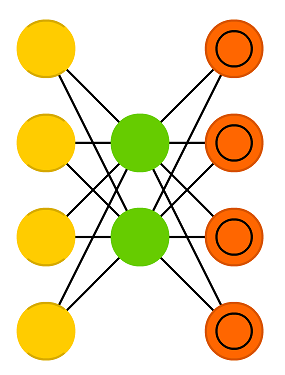
Autoencoder는 입력층, 은닉층, 출력층을 거쳐 입력 데이터가 그대로 다시 출력되도록 동작한다. 왜 입력을 그대로 다시 출력하는 인공신경망을 이용하는지에 대해 의문을 가질 수 있는데 autoencoder는 출력층의 출력이 아니라, 은닉층의 출력을 이용하는 것에 목적이 있다. Autoencoder에서 은닉층의 출력은 다음과 같은 의미와 활용을 갖는다.
- Data Compression : 일반적으로 autoencoder에서는 은닉층 뉴런의 수를 입력층이나 뉴런의 수ㅂ다 작게 설정하기 때문에 은닉층의 출력은 입력 데이터에 대한 압출 데이터로 볼 수 있다.
- Latent representation : 은닉층은 그 자체로 입력 데이터를 잘 표현하기 위한 새로운 공간을 형성하기 때문에 은닉층의 출력은 입력 데이터에 대한 latent representation으로 활용될 수 있다.
딥 러닝에서 autoencoder를 주로 입력 데이터에 대한 latent representation을 생성하기 위해 이용되고 있으며, 다양한 연구에서 autoencoder의 latent representation을 이용한 예측 성능 향상을 실험적으로 보여주었다.
5. Variational Autoencoder (VAE)
VAE는 기존 autoencoder에 확률 개념을 추가한 모델이다. Autoencoder에서는 입력 데이터를 그대로 복원하기 위해 학습이 진행되었다면, VAE에서는 입력 데이터의 확률 분포를 근사하기 위해 학습이 진행된다. 간단하게 이해하자면, autoencoder는 입력 데이터를 사상하기 위한 함수를, VAE는 입력 데이터를 생성하는 확률 분포의 확률밀도함수를 학습한다고 생각할 수 있다. 이 과정에서 VAE는 계산 및 학습의 편의성, 범용성 등을 위해 입력 데이터의 확률 분포를 Gaussian이라고 가정한다. VAE는 입력 데이터가 생성되는 확률 분포 자체를 학습하기 때문에 generative model로도 활용할 수 있다.
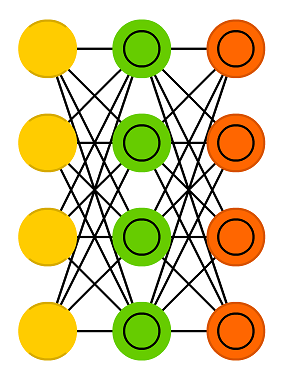
6. Convolutional Neural Network (CNN)
CNN은 아마도 가장 유명한 인공신경망 중 하나일 것이다. CNN은 생명체의 시각 처리 방식을 모방하기 위해 convolution이라는 연산을 인공신경망에 도입함으로써 이미지 처리 분야에서 기존 머신 러닝 알고리즘들을 압도하였다. 2016년에 공개된 알파고에서도 CNN 기반의 딥 러닝 알고리즘이 이용되었다.
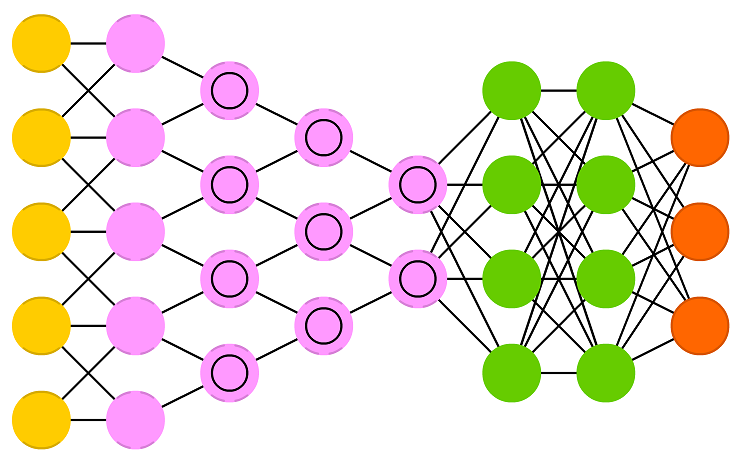
CNN에서는 입력 및 출력 부분에서 뉴런들이 느슨하게 연결되어 있다. 이러한 구조적 특징에 의해 CNN은 DFN이나 RNN에 비해 학습해야하는 가중치의 수가 적으며, 이 덕분에 학습 및 예측이 빠르다는 장점이 있다. 최근에는 CNN의 강력한 예측 성능과 계산상의 효율성을 바탕으로 이미지뿐만 아니라 시계열 데이터에도 CNN을 적용하는 연구가 활발히 진행되고 있다.
7. Deep Residual Network (DRN)
DRN은 "인공신경망에서 계층이 많아질 수록 성능이 증가하는가?" 라는 딥 러닝의 근본적인 질문에서부터 시작한다. DRN 논문의 실험에서는 계층이 많아질 수록 성능이 하락하는 문제는 계층이 많아질 수록 학습이 어려워진다는 점 때문에 발생하는데, 이를 해결하기 위해 DRN 논문의 저자들은 skip connection 이라는 것을 제안했다. 일반적인 인공신경망에서는 데이터가 계층의 순서에 따라 순차적으로 전파되는 것에 비해 DRN에서는 데이터가 그림 8과 같이 다음 계층뿐만 아니라, 더 이후의 계층까지 직접 전달된다.
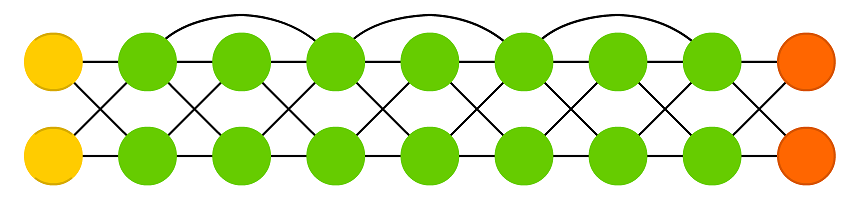
DRN은 주로 CNN과 결합하여 CNN에 skip connection이 추가된 형태로 이용되며, 이러한 인공신경망을 ResNet이라고 한다. ResNet은 다양한 이미지 처리 분야에서 뛰어난 성능을 보여주었다.
8. Generative Adversarial Network (GAN)
요즘 가장 인기 있는 인공신경망을 하나 선택하라면 아마도 대부분은 GAN을 말할 것이다. GAN은 VAE와 같은 generative model이며, 특히 이미지를 생성하는데 있어서 뛰어난 성능을 보여주고 있다. 이외에도 데이터셋에 없는 사람의 얼굴을 스스로 생성하거나, 고흐의 화풍을 모방하여 새로운 그림을 그리는 등 놀라운 결과물들을 보여주었다. 최근에는 GAN이 생성한 그림이 크리스티 경매에서 43만 달러에 낙찰되기도 했다.
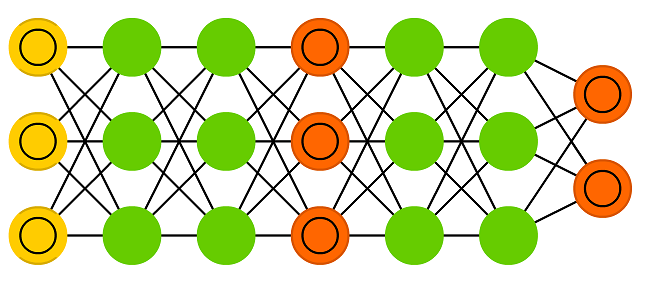
기존의 인공신경망과는 다르게 GAN은 두 개의 인공신경망이 서로 경쟁하며 학습이 진행된다. 이러한 두 개의 인공 신경망을 generator와 discriminator라고 하며, 각각은 서로 다른 목적을 가지고 학습된다. Generator는 주어진 데이터를 보고 최대한 데이터와 비슷한 가짜 데이터를 생성한다. Discriminator는 진짜 데이터와 generator가 만든 가짜 데이터가 입력되었을 때, 어떤 것이 진짜 데이터인지를 판별한다. 이러한 GAN의 동작은 그림 10과 같은 위조 지폐 판별에 관한 문제로 쉽게 생각해볼 수 있다.
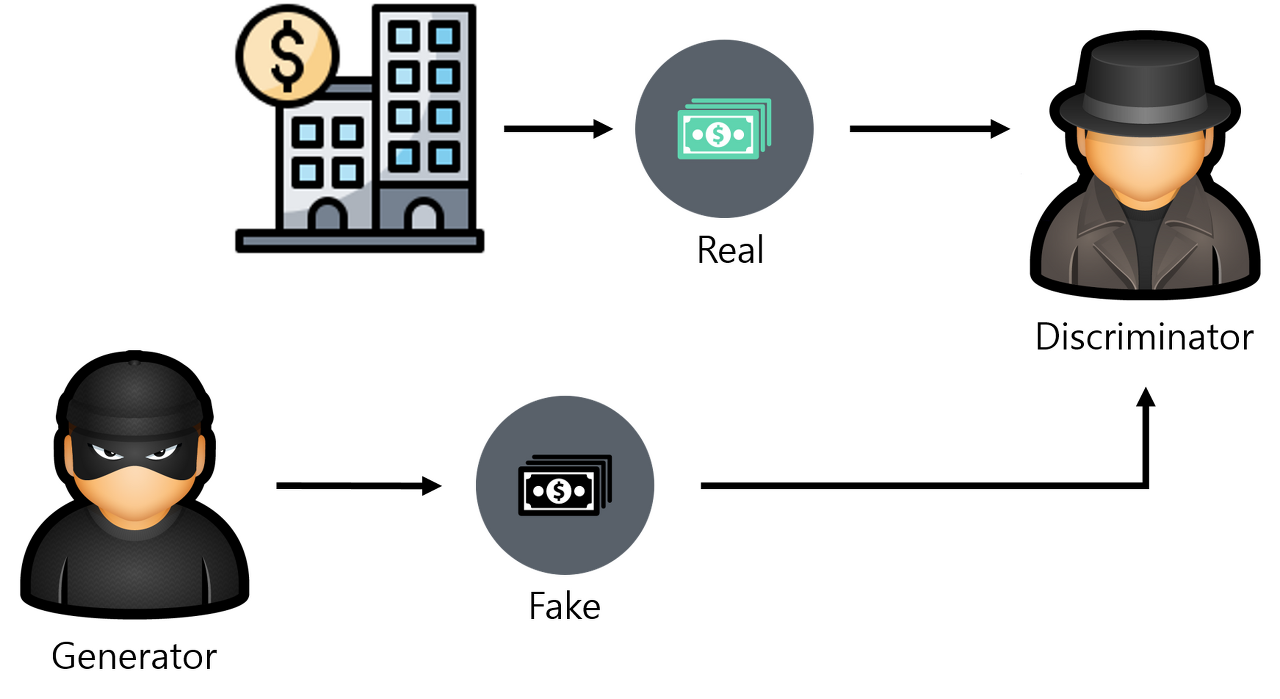
Generator는 discriminator를 속이기 위한 위조 지폐를 만들고, discriminator는 진짜와 가짜 지폐를 구분한다. 이 과정을 계속하여 반복되면 discriminator는 점점 진짜와 가짜 지폐를 잘 구분하게 될 것이고, 이에 따라 generator는 더욱 진짜 같은 가짜를 만들게 될 것이다. 따라서, 이러한 generator와 discriminator의 경쟁을 통해 두 모델의 성능이 모두 향상되는 결과를 얻을 수 있다.
출처 :
'컴퓨터개론' 카테고리의 다른 글
| CURL (0) | 2022.06.20 |
|---|---|
| HTTPS (HyperText Transfer Protocol Secure Socket) (0) | 2022.06.19 |
| 챗봇이란? (0) | 2022.06.17 |
| 음성 인식(speech-to-text), 음성 합성(text-to-speech) (0) | 2022.06.17 |
| Internet of Things (IoT) (0) | 2022.06.17 |



댓글